고정 헤더 영역
상세 컨텐츠
본문
DataFrame에서 데이터 결측치가 존재한다 함은, 말 그대로 없는 데이터(누락 데이터)가 존재한다는 것이다.
보통 None, 혹은 np.nan으로 값이 표현된다.
물론 데이터에 따라서는 전혀 다른 값, 예를 들어 0이나 기타 다른 값을 결측치의 의미로 쓰는 경우도 있긴 하다.
이는 데이터 최초 작성자가 데이터 처리를 어떻게 했느냐에 따라 발생하는 일이긴 한데, 일반적인 경우는 아니다.
어쨌거나 일반적으로 데이터 결측치라 하면, None, 혹은 np.nan 형태의 누락데이터가 존재한다는 의미로 받아들이면 된다.
여기서는 이러한 데이터 결측치를 처리하는 방법에 대해 알아볼 것이다.
먼저 예제로 이용할 DataFrame을 하나 만들어보자.
1. DataFrame 만들기
I. 토끼농장의 DataFrame

어떤 토끼 농장의 주인은 자신의 농장에서 키우는 토끼들에 대한 데이터를 다음과 같이 만들었다.
import pandas as pd
rabbit_dict = {'이름':['콩이', '올망이', '뽀삐', '도롱이', '더 그레이트', '요릉이', '동글이', '쪼꼬미', '복슬이', '까망이'],
'나이':[1, 0, 3, 2, 0, 0, 6, 4, 0, 3],
'몸길이(cm)':[17, 11, 21, 18, 9, 8, 32, 25, 9, 24],
'건강상태':['양호', '양호', '양호', '양호', '양호', '양호', '검진 필요', '검진 필요', '양호', '양호']}
rabbit_df = pd.DataFrame(rabbit_dict)
rabbit_df
하지만 안타깝게도, 농장 주인의 실수로 데이터의 일부가 소실되어 다음과 같이 결측치가 생겼다.
rabbit_lost_dict = {'이름':['콩이', '올망이', '뽀삐', '도롱이', '더 그레이트', '요릉이', '동글이', '쪼꼬미', '복슬이', '까망이'],
'나이':[1, 0, 3, 2, 0, 0, 6, 4, 0, 3],
'몸길이(cm)':[17, 11, 21, 18, None, 8, 32, None, 9, 24],
'건강상태':['양호', '양호', '양호', '양호', None, '양호', '검진 필요', '검진 필요', '양호', '양호']}
rabbit_lost_df = pd.DataFrame(rabbit_lost_dict)
rabbit_lost_df
이제 해당 DataFrame에 나타난 결측치를 다루어보자.
II. 결측치 확인
i) .info()를 이용하는 방법
rabbit_lost_df의 결측치는 간단히 눈에 띄지만, 그래도 메소드를 이용하여 결측치의 존재를 직접 확인해보자.
아래와 같이 .info()를 이용하면 이를 확인할 수 있다.
rabbit_lost_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 10 non-null object
1 나이 10 non-null int64
2 몸길이(cm) 8 non-null float64
3 건강상태 9 non-null object
dtypes: float64(1), int64(1), object(2)
memory usage: 448.0+ bytes
위의 결과에서 Non-Null Count를 보고 결측치의 존재를 확인할 수 있다.
전체 인덱스는 0부터 9까지, 총 10개의 데이터가 존재한다.
그러므로 각각 Column의 Non_Null Count가 10이라면 결측치가 존재하지 않는 것이다.
하지만 '몸길이(cm)', '건강상태'를 보면 각각 Non_Null Count가 8개, 9개인 것을 확인할 수 있으며, 이것으로 결측치가 각각 2개, 1개가 존재함을 확인할 수 있다.
실제로 rabbit_lost_df를 살펴보면 해당 Column에 결측치가 존재하는 것을 확인할 수 있다.
ii) .isna()와 .sum()을 이용하는 방법
위와 같이 .info()를 사용하는 방법 말고도 직접 결측치의 갯수를 확인할 수 있는 방법이 또 있다.
.isna()와 .sum()을 이용하는 것이다.
이에 대해서는 이전에 DataFrame 관련 메소드를 정리한 글에서 다룬 바 있다.
아래 링크를 한 번 참조하고 오자.
관련 링크 : https://kongalmengi.tistory.com/17
[Python](Pandas) DataFrame 관련 메소드-2
DataFrame 관련 메소드 두 번째 시간이다. 여기서 예시로 사용할 DataFrame은 이전 글에서 만들었던 st_df를 이용하기로 한다. 관련 링크 : https://kongalmengi.tistory.com/16 [Python](Pandas) DataFrame 관련 메소드-1 D
kongalmengi.tistory.com
그럼 .isna()를 이용하여 아래와 같이 코드를 구성해보자.
rabbit_lost_df.isna()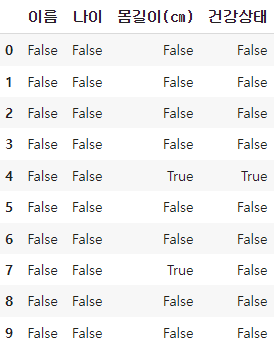
.isna()를 이용하면 위와 같은 결과를 얻을 수 있다.
값이 존재하는 곳에는 False가, 결측치가 존재하는 곳에는 True가 출력된 것을 확인할 수 있다.
여기서 True의 갯수를 세면 그것이 곧 결측치의 갯수가 된다.
이는 .sum()을 이용하는 것으로 원하는 결과를 도출할 수 있다.
rabbit_lost_df.isna().sum()이름 0
나이 0
몸길이(cm) 2
건강상태 1
dtype: int64
위 결과를 통해 '몸길이(cm)'에서 결측치 2개, '건강상태'에서 결측치 1개가 존재함을 확인할 수 있다.
(참고로 .sum()을 적용했을 때의 결과가 왜 결측치의 갯수가 되는지에 대한 설명은 위에 소개한 링크에 있으니 참조.)
2. 결측치 처리
I. 데이터 삭제
가장 간단한 방법은 결측치가 존재하는 데이터를 삭제하는 것이다.
.dropna() 메소드를 이용하면 결측치가 존재하는 데이터를 삭제할 수 있으며, 이를 적용하여 '몸길이(cm)'의 결측치가 존재하는 행을 아래와 같이 삭제할 수 있다.
rabbit_df_del = rabbit_lost_df.dropna(subset=['몸길이(cm)']) # '몸길이(cm) Column의 결측치가 존재하는 열 삭제
rabbit_df_del.reset_index().drop(columns = ['index']) # 인덱스 재정렬 후, 기존 인덱스항 삭제
위의 과정을 거쳤더니 결측치가 존재했던 '더 그레이트'와 '쪼꼬미'의 데이터가 삭제되었다.
II. 평균값으로 대체
i) 결측치 처리
결측치가 존재하는 데이터를 삭제하지 않고, 특정 값으로 대체하여 이용할 수도 있다.
결측치를 평균값으로 대체하는 방법이 그 중 하나다.
그런데 여기서 사용한 DataFrame에 단순히 몸길이의 평균을 대입하지는 않을 것이다.
토끼를 두 그룹으로 나누고, 각각에 대한 평균을 내어 이용할 것이다.
그렇다면 어떤 기준으로 나눌 것인가?
어린 토끼와 성체로 구분할 것이다.
왜?
어린 토끼와 성체 사이에는 몸길이에 확연한 차이가 존재하기 때문이다.
그렇기 때문에 성체의 몸길이와 어린 토끼의 몸길이의 평균을 따로 내어 결측치 처리에 사용한다면, 데이터를 조금 더 정확하게 추정할 수 있을 것이다.
그렇다면 데이터에 기록된 토끼들은 언제 성체가 되는가?
미니렉스 기준, 4~6개월 정도면 성체가 된다고 한다.
이에 따라 나이 기준으로 다음과 같이 두 그룹을 만들 수 있다.
- 어린 토끼 그룹 : 0세
- 성체 그룹 : 1세 이상
이제 아래의 코드를 이용하면 그룹별 평균으로 결측치를 대체할 수 있다.
# '나이'가 0인 경우의 '몸길이(cm)'의 평균 계산
mean_a = rabbit_lost_df.loc[rabbit_lost_df['나이'] == 0, '몸길이(cm)'].mean().round(2)
# '나이'가 1보다 큰 경우의 '몸길이(cm)'의 평균 계산
mean_b = rabbit_lost_df.loc[rabbit_lost_df['나이'] > 1, '몸길이(cm)'].mean().round(2)
# 결측치 대체
rabbit_lost_df.loc[(rabbit_lost_df['나이'] == 0) & (rabbit_lost_df['몸길이(cm)'].isna()), '몸길이(cm)'] = mean_a
rabbit_lost_df.loc[(rabbit_lost_df['나이'] > 1) & (rabbit_lost_df['몸길이(cm)'].isna()), '몸길이(cm)'] = mean_b
rabbit_lost_df
코드에 대한 설명을 하기 전에, 위의 DataFrame을 보면 다음과 같이 '몸길이'에 대한 결측치가 대체된 것을 확인할 수 있다.
- 나이가 0세인 '더 그레이트'의 경우 : 어린 토끼(0세) 몸 길이의 평균인 9.33cm으로 결측치 대체.
- 나이가 4세인 '쪼꼬미'의 경우 : 성체(1세 이상) 몸 길이의 평균인 23.75cm으로 결측치 대체.
참고로 결측치가 생기기 전의 원본 데이터에서 '더 그레이트'와 '쪼꼬미'의 실제 몸길이는 아래와 같다.
- '더 그레이트'의 몸길이 : 9cm
- '쪼꼬미'의 몸길이 : 25cm
이렇게 그룹별 평균을 도입하는 방법으로, 실제 데이터와 추정 데이터 사이의 오차를 크게 줄일 수 있었다.
그러므로 위의 경우에 대해 그룹을 나누어 평균값을 도입하는 판단은, 해당 DataFrame의 결측치를 처리하는데 있어서 충분히 적합한 판단이었다고 할 수 있다.
ii) 코드 설명
자, 그럼 이번에는 위의 코드를 조금 더 살펴보자.
코드 작성 과정을 요약하자면 아래와 같다.
- 그룹별 몸길이의 평균을 구하는 과정에서 .loc[]를 사용 : 나이에 대한 조건을 .loc[]의 행조건으로 넣어 처리.
- 그룹별 몸길이의 평균으로 결측치를 대체 :
a. '나이' = 0을 만족하는 데이터 중에서 결측치가 존재하는 경우 → 두 조건을 &로 묶어 .loc[]의 행조건으로 넣고, 해당 조건을 만족하는 경우에는 '몸길이(cm)' 값을 mean_a(나이=0인 경우의 평균)로 대체.
b. '나이' >= 1을 만족하는 데이터 중에서 결측치가 존재하는 경우 → 두 조건을 &로 묶어 .loc[]의 행조건으로 넣고, 해당 조건을 만족하는 경우에는 '몸길이(cm)' 값을 mean_b(나이>=1인 경우의 평균)로 대체.
여기서 개인적으로 눈여겨 볼만한 포인트를 정리해보자면 아래와 같다.
- 중요 포인트 : .loc[]의 행조건에 &를 이용하면 복수의 조건을 도입할 수 있다.
(마찬가지로, 경우에 따라서는 |를 도입할 수도 있다.)
그 외에도 위의 결측치 처리 과정의 코드를 또 다른 방법으로도 만들 수 있는데, 이는 아래와 같다.
# '나이'가 0인 경우의 '몸길이(cm)'의 평균 계산
mean_a1 = rabbit_lost_df.loc[rabbit_lost_df['나이'] == 0, '몸길이(cm)'].mean().round(2)
# '나이'가 1보다 큰 경우의 '몸길이(cm)'의 평균 계산
mean_b1 = rabbit_lost_df.loc[rabbit_lost_df['나이'] > 1, '몸길이(cm)'].mean().round(2)
# 결측치 대체
rabbit_lost_df['몸길이(cm)'] = rabbit_lost_df['몸길이(cm)'].fillna(value=
rabbit_lost_df.apply(lambda row: mean_a1 if row['나이'] == 0 else
(mean_b1 if row['나이'] > 1 else row['몸길이(cm)']), axis=1)
)
rabbit_lost_df
결과는 앞서 시행한 코드와 동일하다.
여기서 특징적으로 이용된 메소드는 아래와 같이 정리할 수 있다.
- .apply()
- .fillna()
- lambda
뭐, 이런게 있는데 이에 대해서는 나중에 따로 정리하도록 하겠다.
일단은 이런 방법도 있구나 하고 넘어가자.
III. 최빈값으로 대체
앞에서는 결측치를 평균값으로 대체하는 방법에 대해 알아봤다.
하지만 데이터를 다루다보면, 항상 평균값을 이용할 수 있는 것은 아니다.
범주형 데이터에 대해서는 대체로 수학적 평균값이 별 의미가 없다.
※ 여기서 범주형 데이터란?
범주형 데이터는 크게 명목형 데이터와 순서형 데이터로 나뉜다.
각각의 경우에 포함되는 대표적인 데이터의 예시는 아래와 같다.
- 명목형 데이터 : 성별, 출신 학교, 국가, 도시 등등...
- 순서형 데이터 : 성적 순위
이런 범주형 데이터는 대부분 문자로 이루어져 있다. 순서형 데이터같은 경우에는 숫자도 가능하지만, 이런 경우는 불연속적인 숫자 분포를 이용한다. 또한, 순서형 데이터라 해도 문자형이 가능하다.(예:성적평가지표[수, 우, 미, 양, 가], 혹은 [A, B, C, D, F])
이러한 점을 생각해볼 때, 예시로 사용한 rabbit_df에서 몸 길이는 숫자형 데이터(순서형이 아님.), 그리고 건강상태는 범주형 데이터임을 알 수 있다.
다시 본론으로 돌아와서, rabbit_lost_df의 '건강상태' 결측치를 처리할 것이다.
여기서 '건강상태'항목은 범주형 데이터로써, 수리적 평균값이 의미가 없다.
이러한 이유로 최빈값으로 대체하는 방식을 이용하여 결측치를 처리할 것이다.
먼저 '건강상태' Column의 최빈값이 무엇인지 확인해보자.
rabbit_lost_df['건강상태'].value_counts()양호 7
검진 필요 2
Name: 건강상태, dtype: int64
위의 결과를 통해 토끼의 건강상태에 대한 최빈값은 '양호'임을 알 수 있다.
이에 따라 '건강상태'의 결측치를 다음과 같이 '양호'로 대체할 수 있다.
rabbit_lost_df.loc[rabbit_lost_df['건강상태'].isna()==True, '건강상태'] = '양호'
rabbit_lost_df
위의 결과를 원본 데이터인 rabbit_df와 비교해보자. 약간의 오차는 존재하지만, 그래도 결측치 처리 과정이 상당히 적합했음을 확인할 수 있다.
IV. 결측치 처리시, 발생할 수 있는 문제점
앞에서 rabbit_df 예제를 통해 결측치 처리 방법에 대해 간단히 알아봤다. 하지만 예제에서 소개한 결측치 처리방법이 항상 올바른 결과를 도출하는 것은 아니다.
예를 들어, rabbit_df에서 '쪼꼬미'의 건강상태가 결측치였다고 가정해보자. 이런 경우에 건강상태의 최빈값으로 결측치를 대체하면 '양호'를 입력해야 하는데, 이는 실제 상태인 '검진 필요'와 완전히 반대된다.
뿐만 아니라, 만약 건강상태의 데이터가 '양호'와 '검진 필요'가 비슷하게 분포해 있는 상황을 생각해보자. 이런 경우에는 최빈값이 의미를 잃게 되며, 작은 차이로 최빈값이 선정되더라도 결측치 처리시 오차가 많아지게 된다.
여기서 포인트는, 결측치 처리 과정은 실제 데이터와 똑같은 상태로 데이터를 복원할 수 없으며, 항상 오차를 동반할 수 있다는 점이다.
다만 데이터를 처리하는 사람은, 대체된 결측치가 최대한 오차와 거리가 멀도록 적절한 대체값을 찾을 뿐이다.
예제에서는, 토끼들의 몸길이에 대한 결측치를 처리하는 과정에서 그룹을 나누어 평균을 구하고, 조건에 따라 결측치의 대체값을 달리 적용한 것이 바로 적절한 대체값을 적용하기 위한 과정이었다.
이렇게 적절한 대체값을 찾는 과정에는 정답이 없다.
상황에 따라서 평균을 적용하는 것이 좋을 수도 있고, 최빈값을 적용하는 것이 좋을 수도 있다.
때로는 전혀 다른 값으로 분류하는 것이 좋을 수도 있고, 데이터를 아예 삭제하는 것이 좋을 수도 있다.
정답은 없다.
어떤 방법을 선택할지는 그저 데이터를 다루는 사람의 결정이고 몫일 뿐이다.
'파이썬 배우기 - (ver.1) > Pandas 라이브러리 기초' 카테고리의 다른 글
| [Python](Pandas) 빈 DataFrame 채우기 (0) | 2024.03.09 |
|---|---|
| [Python](Pandas) .groupby() 메소드 (0) | 2024.02.22 |
| [Python](Pandas) 데이터 가공-2 : DataFrame의 행과 열 추출하기, 그리고 .loc[] (0) | 2024.02.19 |
| [Python](Pandas) 데이터 가공-1 : DataFrame에 새로운 Column 추가하기 (0) | 2024.02.18 |
| [Python](Pandas) DataFrame 합치기(concat, join, merge) (0) | 2024.02.16 |




